(本博客中使用的数据已全部替换为随机数)
在上一次的工作中,我将文件的批量处理执行地更加彻底,基本上驾轻就熟了。并且发现了plyr里很有用的工具:ldply来配合我的文件批处理。
批量读取文件
months <- 201801:201810
jdall <- list()
for(i in 1:length(months)){
path <- paste(c("D:\\data\\sx_raw\\交调数据\\jd",months[i],".csv"),collapse = "")
jdall[[i]] <- read.csv(path)
}
names(jdall) <- months批量查看维度
sapply(jdall, dim)## 201801 201802 201803 201804 201805 201806 201807 201808 201809 201810
## [1,] 6512 6487 6599 6641 30691 35358 28035 6500 6284 33154
## [2,] 24 24 24 24 24 24 24 24 24 24批量预处理
jdalls <- lapply(jdall, handle_gather)在这一步,我想让01~10各月的index取交集,达到数据统一口径的目的。所以我先将取得交集的index存到变量usefulstation里,然后用它过滤数据。
- 首先提取各DF中的index列,存在一个列表里,叫l;
- 使用Reduce函数,递归地求交集,将交集存在usefulstation里;
- 检验递归交集的长度,看此过程是否出错;
- 对各DF进行过滤,这是一个分而治之的问题,首先找到一个解决方案,然后再扩充到所有DF中;
- 使用dplyr的filter函数进行过滤;
- 使用一个匿名函数,以便方便应用lapply;
- 检验过滤后的结果;
l <- lapply(jdalls,`[[`,"index")
usefulstation <- Reduce(intersect,l)
length(usefulstation)## [1] 4691jdalls <- lapply(jdalls, function(x) filter(x,index %in% usefulstation))sapply(jdalls, dim)## 201801 201802 201803 201804 201805 201806 201807 201808 201809 201810
## [1,] 4691 4691 4691 4691 4691 4691 4691 4691 4691 4691
## [2,] 29 29 29 29 29 29 29 29 29 291. 总体情况
总量分析
sapply(jdalls,caculate_all_frecars)## 201801 201802 201803 201804 201805 201806 201807 201808 201809 201810
## 6838 4841 7281 7855 7695 7418 7445 7562 7813 7849分等级分析
这里我想对每个DF使用caculate_frecarsmean函数,如果用lapply结果依旧储存在列表里,而我想让它储存在DF里,尝试用sapply,结果如下,sapply并不知道我想干什么。
sapply(jdalls, caculate_frecarsmean, "level")## 201801 201802 201803 201804 201805
## level Character,4 Character,4 Character,4 Character,4 Character,4
## Wmean Numeric,4 Numeric,4 Numeric,4 Numeric,4 Numeric,4
## 201806 201807 201808 201809 201810
## level Character,4 Character,4 Character,4 Character,4 Character,4
## Wmean Numeric,4 Numeric,4 Numeric,4 Numeric,4 Numeric,4尝试使用plyr里的ldpply,l表示按列表元素切分,d表示返回数据框,得到新列.id,便于和原有数据融合。
ldpply实际上是将lapply的计算结果rbind到一起。
ldply(jdalls, caculate_frecarsmean, "level") %>% head(12) %>% kable()| .id | level | Wmean |
|---|---|---|
| 201801 | 普通国道 | 0.492 |
| 201801 | 国家高速 | 0.496 |
| 201801 | 普通省道 | 0.503 |
| 201801 | 省级高速 | 0.511 |
| 201802 | 国家高速 | 0.494 |
| 201802 | 普通国道 | 0.498 |
| 201802 | 普通省道 | 0.499 |
| 201802 | 省级高速 | 0.505 |
| 201803 | 普通省道 | 0.488 |
| 201803 | 普通国道 | 0.491 |
| 201803 | 国家高速 | 0.501 |
| 201803 | 省级高速 | 0.537 |
不过结果是长形的,如果需要可以整型成宽型的。
ldply(jdalls, caculate_frecarsmean, "level") %>% dcast(.id~level) %>% kable()## Using Wmean as value column: use value.var to override.| .id | 国家高速 | 普通国道 | 普通省道 | 省级高速 |
|---|---|---|---|---|
| 201801 | 0.496 | 0.492 | 0.503 | 0.511 |
| 201802 | 0.494 | 0.498 | 0.499 | 0.505 |
| 201803 | 0.501 | 0.491 | 0.488 | 0.537 |
| 201804 | 0.492 | 0.490 | 0.509 | 0.483 |
| 201805 | 0.511 | 0.500 | 0.500 | 0.511 |
| 201806 | 0.473 | 0.504 | 0.506 | 0.493 |
| 201807 | 0.497 | 0.487 | 0.483 | 0.514 |
| 201808 | 0.477 | 0.511 | 0.501 | 0.443 |
| 201809 | 0.504 | 0.501 | 0.522 | 0.503 |
| 201810 | 0.527 | 0.496 | 0.482 | 0.508 |
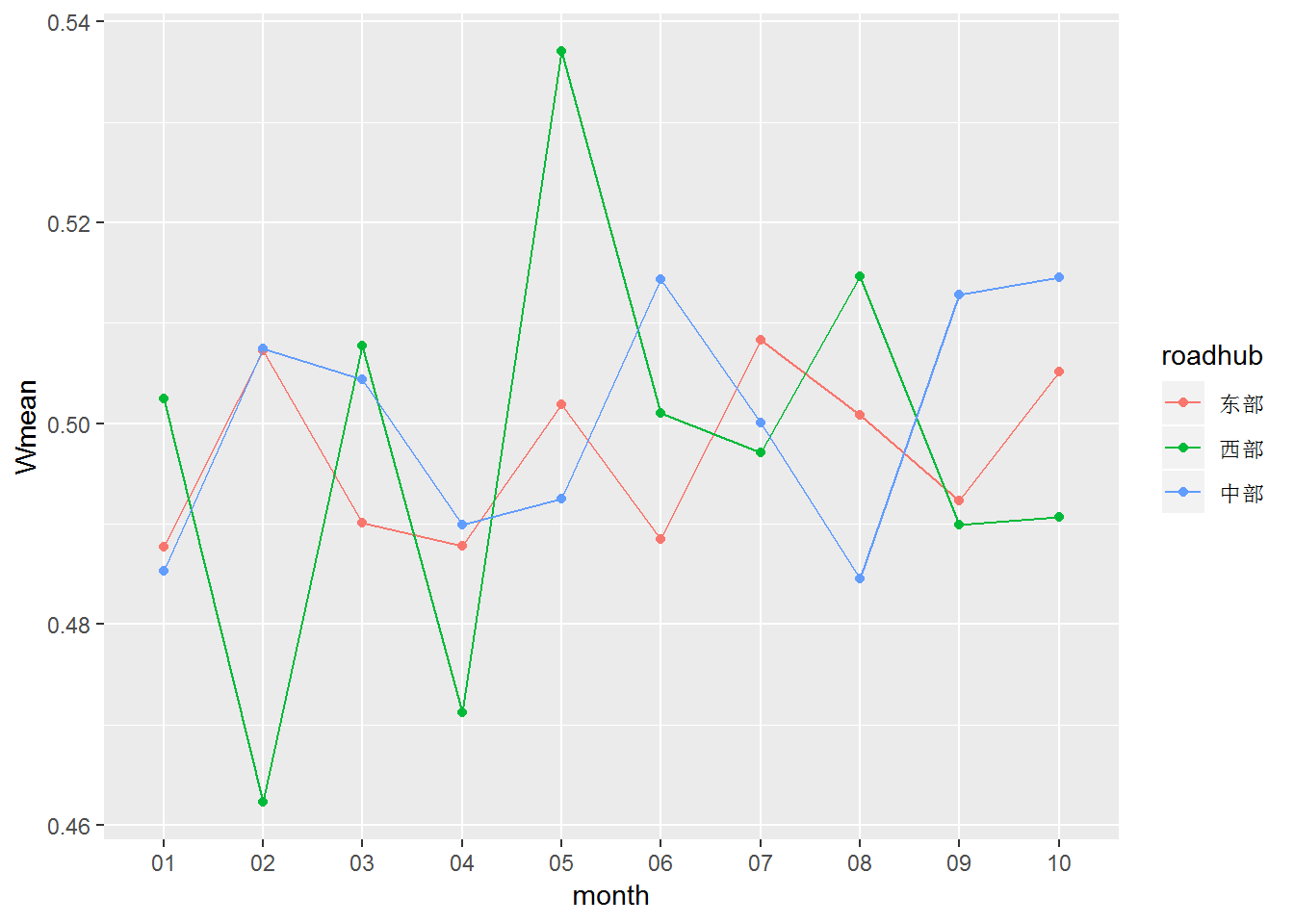
2. 面
分区域分析
- base::transform是改变原DF的某一列;
- dplyr::mutate是增加一个新列;
用ggplot画平行坐标图时,不需要整型成宽型;
ldply(jdalls, caculate_frecarsmean, "roadhub") %>% mutate(month=str_sub(.id,-2,-1)) %>%
ggplot(aes(x=month,y=Wmean,group=roadhub,color=roadhub))+geom_point()+geom_line()